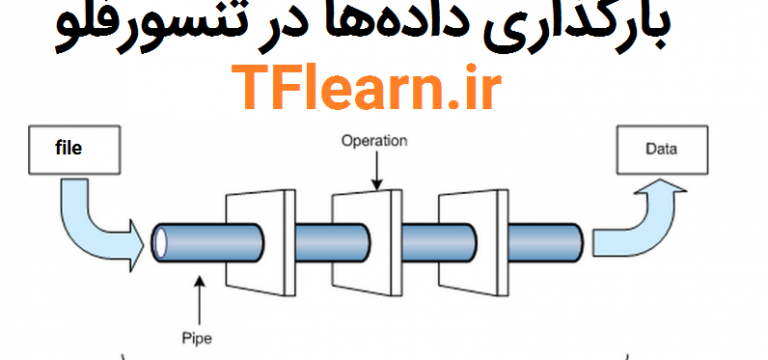
یکی از گامهای اولیه و اساسی در برنامههای یادگیری ماشینی، بارگذاری و فراخوانی مجموعه دادهها است. در نسخهی ۱٫۰ TensorFlow نسبت به نسخههای پیشین ابزارهایی جدیدی به این منظور گنجاندهشده است. در ادامه به معرفی آنها میپردازیم.
فراخوانی دادهها در TensorFlow
به طور کلی سه روش اصلی برای دریافت دادهها در برنامههای TensorFlow وجود دارد:
خوراندن (Feeding): کد پایتون دادهها در هر گام اجرا فراهم میکند.
خواندن از فایل: یک خط لوله ورودی دادهها را در ابتدای اجرای گراف محاسباتی TensorFlow میخواند.
پیش بارگذاری دادهها: یک متغیر یا ثابت در گراف محاسباتی تمام دادهها را در خود نگه میدارد (برای مجموعه دادههای کوچک).
خوراندن (Feeding)
سازوکار خوراند (Feed) در TensorFlow به شما این امکان را میدهد که دادهها را در هر تانسور موجود در گراف محاسباتی وارد کنید. سپس فرآیند اجرای پایتون میتواند دادهها را به طور مستقیم به گراف محاسباتی وارد کند.
فرآیند خوراند را با استفاده از دستور feed_dict در یک فراخوانی ()run یا ()eval محاسبات را مقداردهی اولیه مینماید.
with tf.Session():
input = tf.placeholder(tf.float32)
classifier = ...
print(classifier.eval(feed_dict={input: my_python_preprocessing_fn()}))
بااینوجود که میتوان مقدار هر تانسور اعم از متغیرها و ثوابت را با استفاده از خوراند داده جایگزین کرد، اما بهترین راه، استفاده از یک
tf.placeholderاست. جانگهدار یا placeholder -همانطور که قبلاً نیز اشارهشده است- با هدف استفاده به عنوان مقصد خوراند داده ایجاد میشود. در نتیجه نه مقداردهی اولیه میشود و نه شامل دادهای است. اگر placeholder را بدون خوراند داده، در کد مورداجرا قرار دهید تولید خطا خواهد کرد.
یکی از مثالهایی که از نحوهی استفاده از placeholder و خوراند داده میتوان گفت، استفاده از آن در مسئله بازشناسانی MNIST است که در آنجا نیز مورد شرح قرارگرفته است.
خواندن از فایل
یک خط لوله برای خواندن رکوردهای از فایل دارای مراحل زیر است:
- لیستی از نام فایلها
- در هم ریختن نام فایلها (قرار دادن این بخش اختیاری است)
- حد دورههای اجرا (قرار دادن این بخش اختیاری است)
- صف نام فایل
- یک خواننده برای قالب فایل
- یک کدگشا برای رکوردهای خوانده شده توسط خواننده
- پیش پردازش (اختیاری)
- صف نمونه
نام فایل ها، درهم ریختن و حدود دوره ی اجرا
برای لیستی از نام فایلهای موجود، یک تانسور رشتهای ثابت را استفاده کنید (شبیه [“file0”, “file1”] یا [(“file%d” % i) for i in range(2)] ) یا از تابع tf.train.match_filenames_once بهره بگیرید.
سپس لیست نامهای فایلها را به tf.train.string_input_producer بدهید.
tf.train.string_input_producer یک صف FIFO برای نگهداری نام فایلها تا وقتیکه خوانندهی فایل به آنها نیازمنداست، ایجاد میکند. tf.train.string_input_producer گزینههایی برای هم در هم ریختن نامها و تنظیم تعداد دوره اجرایی دارد. به این صورت که تمام لیست را در هر دوره به صف اضافه میکند و اگر shuffle=True قرار دهید، در هر دوره نام فایلها را درهم میریزد. این رویه یک فرم یکنواخت نمونهبرداری از فایلها را فراهم میکند و مانع کم یا بیش نمونهگیری میشود.
اجراکننده صف در نخی مجزا از نخ اجرای خواننده که نام فایلها را از صف بیرون میکشد اجرا میشود، بنابراین فرآیند در هم ریختن و از صف کشیدن خواننده فایل را مسدود نمیکنند.
قالبهای فایلها
با توجه به قالبهای مختلف ذخیرهسازی دادهها در فایلها، باید خواننده فایل متناسب را انتخاب نمود و صف نام فایلها را به آن ارائه داد.
متد خواند یک کلید را برای شناسایی فایل و رکورد تولید میکند (که برای دیباگ کردن رکوردهای پیچیده مفید است) و همچنین مقدار رشتهای نیز ایجاد میشود. گاهی دادهها در قالب رشتهای یا بایتی هستند که پس از خواندن باید از کدگشاها (Decoder) برای تبدیل آنها به تانسورهایی که نمونههای مسئله ما را میسازند استفاده کرد.
در ادامه چند نمونه از این قالبهای فایلی را مورد بررسی قرار میدهیم.
فایلهای CSV
برای خواندن فایلهای در قالب comma-separated value) CSV) از دستور tf.TextLineReader در کنار tf.decode_csv استفاده کنید. برای مثال:
filename_queue = tf.train.string_input_producer(["file0.csv", "file1.csv"])
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
# Default values, in case of empty columns. Also specifies the type of the
# decoded result.
record_defaults = [[1], [1], [1], [1], [1]]
col1, col2, col3, col4, col5 = tf.decode_csv(
value, record_defaults=record_defaults)
features = tf.stack([col1, col2, col3, col4])
with tf.Session() as sess:
# Start populating the filename queue.
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
for i in range(1200):
# Retrieve a single instance:
example, label = sess.run([features, col5])
coord.request_stop()
coord.join(threads)
هر اجرا از دستور read ، یک خط را از فایل میخواند. سپس دستور decode_csv نتایج را به لیستی از تانسورها تبدیل میکند. آرگومان record_defaults نوع تانسورهای حاصله را مشخص میکند و یک مقدار پیشفرض برای مقادیری که در رشته ورودی گمشدهاند، تنظیم میکند.
قبل از فراخوانی read و یا eval برای اجرای read، باید tf.train.start_queue_runners را فراخوانی کنید تا صف را پر کند.
در غیر این صورت دستور read درحالیکه منتظر نام فایلها از صف است، مسدود میشود.

سلام و عرض ادب
من دارم کدهای cifar10 رو در ژوپیتر اجرا میکنم اما در زمان import cifar 10 اروری که میده ماژول رو پیدا نمیکنه
من کد مربوط به دانلود دیتا ست رو در کدوم دایرکتوری باید قرار بدم؟
ممنون
درود و سپاس
بخش مجموعه دادگان در دست گردآوری است و مقالات CIFAR و RNN نیز در حال تدویناند و به زودی بر روی سایت منتشر میشوند و پاسخ سوال خود را خواهید یافت.
اما نکتهای در مورد سوال شما وجود دارد، چنین کدی (“import cifar10”) در مثالهای آموزشی TensorFlow ندیدم و احتمالا اشتباهی در درج این کد رخ داده است.
سلام و احترام
ایا خواندن دیتاست برای هر قسمت تست و ترین جدا گانه انجام میشود؟
ممنون
بسته به استراتژی برنامه شما است. شما میتوانید با توجه به روشهایی که در بالا توضیح داده شد، مجموعه دادگان (آموزش و آزمون) را یک مرحله وارد برنامه کنید و یا بلعکس.
سلام
برای استفاده از یک معماری از پیش اموزش دیده بایدچکار کنم
خواندن تصویر+ معماری (الکس نت)
ممنون