بهطور معمول در آموزشهای زبانها و ابزارهای برنامهنویسی و یا برنامهسازی، سنتی دیرینه وجود دارد و آن سنت این است که اولین مثالی که آموخته میشود، برنامه چاپ “HELLO WORLD” است. همانند زبانهای برنامهنویسی که مثال Hello world دارند، یادگیری ماشین نیز مسئلهای ابتدایی دارد که از آن با نام MNIST یادد میشود.
Mnist یک مجموعه داده ساده در زمینه بینایی ماشین(کامپیوتر) است. این مجموعه داده شامل تصاویری از ارقام دستنویس انگلیسی مانند تصاویر زیر است که به کوشش Lecun جمع آوری شده است:

همچنین در این مجموعه، برچسبهایی برای هر تصویر وجود دارد که بیانگر این است که هر تصویر نمایان گر چه رقمی است.
برای مثال این برچسبها برای تصاویر بالا به ترتیب از چپ به راست عبارتاند از ۵و۰و۴و۱٫
دادههای MNIST
دادههای MNIST بر روی وبسایت پروفسور Yann LeCun قرارگرفته است. برای راحتی شما، تعدادی کد پایتون در تنسورفلو قرار دادهشده که به صورت خودکار مجموعه داده را دانلود و نصب مینماید .شما میتوانید مجموعه دادهها با استفاده از کد زیر فراخوانی و دانلود نمایید. (برای اطلاعات بیشتر به این مطلب مراجعه کنید)
دادههای دانلود شده به سه بخش تقسیم میشوند، ۵۵٫۰۰۰ نمونه (داده) به عنوان مجموعه داده آموزشی ، ۱۰۰۰۰۰ نمونه برای تست و ۵۰۰۰ نمونه برای اعتبار سنجی. این تقسیم بسیار مهم است . همانطور که ذکر شد، هر داده MNIST دو بخش دارد، یک تصویر از یک رقم دستنویس و برچسب مرتبط با آن.
ما از این پس تصاویر را “xs” و برچسبهای مرتبط را “ys” مینامیم. هر دو مجموعه آموزش و تست xs و ys دارند، برای مثال تصاویر آموزشی mnist.train.images و برچسبهای آموزشی mnist.train.images هستند.
اندازه هر تصویر ۲۸*۲۸ پیکسل است. ما میتوانیم هر تصویر را بهصورت آرایهای بزرگ از اعداد تفسیر کنیم:
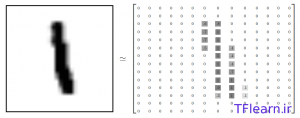
همچنین میتوان این آرایه را به یک بردار با اندازه ۲۸*۲۸=۷۸۴ تبدیل کرد. مهم نیست که ما آرایه را چگونه به بردار تبدیل کردیم، فقط باید همین روال را برای همه دادهها به یک صورت انجام دهیم.
اگر از این بعد به تصاویر MNIST نگاه کنیم، میتوانیم این بردارهای تصاویر MNIST را گروهی از نقاط در یک فضای برداری ۷۸۴ بعدی هستند. اگر این درک مطلب قدری برای شما دشوار است و یا تجسم این فضاها و دادهها قدری پیچیده به نظر میرسد، بهتر است سری به این پست بزنید که در آن مجموعه دادهی MNIST بصری سازی (Visualisation) شده است.
اما شاید سؤالی که برای شما نیز مطرح میشود، مسطح سازی دادهها بدون توجه به ساختار ۲بعدی تصاویر است. ممکن است شما نیز بر این باور باشید که این کار آنچنان روش خوبی نیست. بهترین روش بینایی ماشین برای بهرهبرداری از این ساختار (دوبعدی) تصاویر در مطالب بعدی توضیح داده خواهد شد. اما این عمل مسطح سازی برای روش سادهای که در این آموزش استفاده میشود (یعنی رگرسیون softmax است) بد نیست.
با اوصاف بالا، mnist.train.images یک تانسور است ( یک آرایهی n بعدی) با ابعاد [۵۵۰۰۰و۷۸۴] است.اندیس بعد اول بیانگر تصاویر و اندیس بعد دوم بیانگر پیکسلهای هر تصویر است. هر مقدار در یک تانسور پیکسلی در یک تصویر خاص است که شدت نور آن پیکسل بین ۰ و ۱ است.. تصویر زیر تجسمی از این تانسور است.

برچسبهای مرتبط در MNIST اعدادی بین ۰ و ۹ هستند که بیانگر آن هستند که تصویر کدام رقم ارائهشده است. برای اهداف این آموزش، میخواهیم که برچسبهای ارقام به شکل ” بردارهای one-hot” باشند.
بردار one-hot برداری است در یک بعد ۱ و در بقیه ابعاد صفر است. در اینجا nامین رقم بهصورت برداری نمایش داده میشود که nامین بعد آن ۱است. یعنی برای مثال ۳ به صورت خواهد بود.به همین ترتیب مجموعه برچسبها(mnist.train.labels) یک آرایهای از اعداد است در ابعاد [۵۵۰۰۰, ۱۰] که به صورت شماتیک در شکل زیر مشاهده میکنید.

برای آشنایی بیشتر یک پیاده سازی بر روی MNIST به این مطلب مراجعه کنید.